
Trình tạo video AI
Biến Ảnh Tĩnh Thành Video Động Bằng Hunyuan IP2V

Trong thế giới sáng tạo nội dung số đang phát triển không ngừng, video ngày càng khẳng định vị thế là một công cụ mạnh mẽ để thu hút sự chú ý và truyền tải thông điệp. Tuy nhiên, việc sản xuất video chất lượng cao thường đòi hỏi nhiều thời gian, công sức và kỹ năng chuyên môn. Liệu có giải pháp nào giúp chúng ta tạo ra những video ấn tượng một cách nhanh chóng và dễ dàng hơn không? Câu trả lời nằm ở Hunyuan Video, một mô hình video tiên tiến, kết hợp cùng quy trình Image-Prompt to Video (IP2V) đầy sáng tạo.
Bài viết này sẽ đưa bạn khám phá sức mạnh của Hunyuan IP2V, một phương pháp độc đáo để biến những hình ảnh tĩnh thành những thước phim sống động, mở ra những cơ hội mới cho việc sáng tạo nội dung đa dạng và hấp dẫn.
Giải Mã Hunyuan IP2V: Biến Ý Tưởng Thành Hiện Thực
Hunyuan Video là một mô hình video nội địa, có khả năng chuyển đổi mô tả văn bản thành video một cách ấn tượng. Tuy nhiên, điều gì sẽ xảy ra nếu bạn muốn biến một hình ảnh thành video? Mặc dù Hunyuan chưa phát hành mô hình image-to-video (img2vid) trực tiếp, nhưng chúng ta có thể tận dụng quy trình Image-Prompt to Video (IP2V) để đạt được hiệu ứng tương tự.
Quy trình IP2V cho phép bạn kết hợp một hình ảnh và một đoạn mô tả văn bản để tạo ra một video hoàn chỉnh. Ví dụ, bạn có thể cung cấp một hình nền và thêm một người vào cảnh bằng một đoạn mô tả, sau đó tạo ra một video như ý muốn.
Sự Khác Biệt Giữa img2vid và IP2V
Điều quan trọng cần phân biệt là sự khác biệt giữa img2vid và IP2V. Quy trình img2vid sử dụng hình ảnh đầu vào làm khung hình đầu tiên của video. Trong khi đó, quy trình IP2V sử dụng hình ảnh như một phần của lời nhắc (prompt). Nó khai thác ý tưởng từ hình ảnh, nhưng không sử dụng nó làm khung hình đầu tiên.
Quy trình Hunyuan IP2V mở ra vô vàn khả năng sáng tạo trong nhiều lĩnh vực khác nhau.
Tạo Bối Cảnh Độc Đáo Từ Hình Ảnh
Bạn có thể dễ dàng sử dụng một hình ảnh có sẵn làm bối cảnh cho video của mình. Ví dụ, hãy sử dụng hình ảnh một đường hầm và thêm một người vào video bằng đoạn mô tả sau:
“Một người phụ nữ xinh đẹp thời trang với mái tóc vàng dài, váy ngắn đen, áo trắng, giày cao gót, đang đi về phía máy quay, , máy quay phóng to.”
Lưu ý rằng bạn cần chèn mã thông báo (token) vào lời nhắc để chỉ định vị trí bạn muốn chèn hình ảnh.
Hunyuan IP2V xử lý tốt việc tạo ra một người đang đi trong đường hầm, mặc dù bạn không đề cập đến đường hầm trong lời nhắc. Quy trình này sử dụng mô hình ngôn ngữ thị giác lớn (visual LLM) để phân tích và đưa hình nền vào video.
Một điểm quan trọng cần lưu ý là đường hầm trong hình ảnh và video có vẻ giống nhau nhưng không hoàn toàn giống hệt. Điều này là do visual LLM đọc hình ảnh và chuyển đổi nó thành mã thông báo hình ảnh (image tokens). Chúng mô tả cảnh và do đó, ảnh hưởng đến video. Tuy nhiên, khác với IP-adapter, nó không sao chép hình ảnh vào video.
Biến Hình Ảnh Tĩnh Thành Video Động
Hunyuan Video là một công cụ tuyệt vời cho những người sáng tạo nội dung. Chất lượng video vượt trội của nó có tiềm năng lớn trong việc tạo ra những đoạn phim B-roll (những cảnh quay bổ sung cho video chính) ấn tượng.
Mặc dù có sẵn các đoạn phim B-roll miễn phí bản quyền, nhưng số lượng và sự đa dạng của chúng còn hạn chế so với hình ảnh miễn phí bản quyền. Vậy tại sao bạn không sử dụng quy trình Hunyuan IP2V để biến một hình ảnh miễn phí bản quyền thành một đoạn phim B-roll độc đáo?
Giả sử bạn đang làm một video về kế hoạch tài chính. Hình ảnh một người phụ nữ đang làm việc có thể là một lựa chọn tuyệt vời cho đoạn B-roll.
Sử dụng hình ảnh này làm đầu vào và chỉ sử dụng mã thông báo hình ảnh làm lời nhắc văn bản:
Bạn sẽ có ngay một đoạn B-roll ấn tượng!

Để bắt đầu hành trình sáng tạo video với Hunyuan IP2V, bạn cần làm quen với ComfyUI, một giao diện người dùng đồ họa mạnh mẽ cho Stable Diffusion.
Xem thêm:
Chuyển Động Cho Video với Kling Ai
Tạo Video AI Miễn Phí: MiniMax AI Đã Sẵn Sàng “So Găng” với Sora?
Phần Mềm Cần Thiết
Chúng ta sẽ sử dụng ComfyUI, một giải pháp thay thế cho AUTOMATIC1111. Bạn có thể sử dụng nó trên Windows, Mac hoặc Google Colab.
Nếu bạn là người mới bắt đầu sử dụng ComfyUI, hãy tham khảo hướng dẫn dành cho người mới bắt đầu.
Các Bước Thực Hiện
Các hướng dẫn sau đây dành cho ComfyUI trên máy tính cục bộ của bạn (Windows hoặc Linux).
Nếu bạn sử dụng ComfyUI Colab notebook, bạn không cần tải xuống các mô hình (bước 1 và 2). Chọn các nút tùy chỉnh HunyuanVideoWrapper và VideoHelperSuite khi khởi động notebook. Sử dụng loại thời gian chạy L4 (quy trình này cần 20GB VRAM). Bắt đầu từ bước 3.
Bước 0: Cập Nhật ComfyUI
Trước khi tải quy trình làm việc, hãy đảm bảo ComfyUI của bạn được cập nhật. Cách dễ nhất để thực hiện việc này là sử dụng ComfyUI Manager.
Nhấp vào nút Manager trên thanh công cụ trên cùng.
Chọn Update ComfyUI.
Khởi động lại ComfyUI.
Bước 1: Tải Xuống Mô Hình Video
Tải xuống mô hình hunyuanvideoFastVideo720fp8e4m3fn.safetensors và đặt nó trong ComfyUI > models > diffusionmodels.
Bước 2: Tải Xuống VAE
Tải xuống hunyuanvideovae_bf16.safetensors.
Tệp VAE này khác với tệp do ComfyUI phát hành và được sử dụng trong hướng dẫn text-to-video. Đổi tên nó thành hunyuanvideovae_bf16-kj.safetensors.
Đặt nó trong ComfyUI > models > vae.
Bước 3: Tải Quy Trình Làm Việc
Tải xuống tệp JSON quy trình làm việc Hunyuan video.
Kéo và thả nó vào ComfyUI.
Bước 4: Cài Đặt Các Nút Bị Thiếu
Nếu bạn thấy các khối màu đỏ, bạn không có nút tùy chỉnh mà quy trình này cần.
Nhấp vào Manager > Install missing custom nodes và cài đặt các nút bị thiếu.
Khởi động lại ComfyUI.
Bước 5: Chạy Quy Trình Làm Việc
Tải hình ảnh vào nút Load Image.
Nhấp vào nút Queue để tạo video.
Lần đầu tiên chạy quy trình làm việc sẽ mất thời gian vì nó sẽ tải xuống một số tệp mô hình.
Mẹo: Bạn cũng có thể tăng tốc độ tạo video bằng TeaCache.

Giảm Mẫu Mã Thông Báo Hình Ảnh
Mức độ ảnh hưởng của hình ảnh đến video được kiểm soát bởi imagetokenselection_expr. Giá trị ::4 giảm mẫu mã thông báo hình ảnh để chỉ sử dụng một trong bốn mã thông báo. Sử dụng giá trị cao hơn để giảm ảnh hưởng của hình ảnh, ví dụ: ::8 hoặc ::16.
Tăng hệ số giảm mẫu lên ::16 sẽ thay đổi nền thành một tòa nhà đổ nát ngoài trời với hình vẽ graffiti. Đường hầm trở thành một hành lang tương tự. Người phụ nữ được kiểm soát bởi lời nhắc, vì vậy cô ấy vẫn mặc trang phục tương tự.
Tăng khả năng giảm mẫu lên ::256 sẽ loại bỏ đường hầm. Cô ấy đang đi bộ trong một không gian mở trong một tòa nhà đổ nát, nhưng hình vẽ graffiti vẫn ở khắp mọi nơi.
Các Tùy Chọn Khác Để Truyền Mã Thông Báo Hình Ảnh
Mô hình llava-llama-3 có 576 mã thông báo hình ảnh. Thay vì giảm mẫu, bạn có thể thử nghiệm với việc chỉ truyền một phần mã thông báo.
- :128 – 128 mã thông báo đầu tiên.
- -128: – 128 mã thông báo cuối cùng.
- :128, -128: – 128 mã thông báo đầu tiên và 128 mã thông báo cuối cùng.

Hunyuan IP2V không chỉ là một công cụ, mà còn là chìa khóa mở ra những tiềm năng sáng tạo vô tận trong kỷ nguyên AI, giúp bạn tạo ra những video độc đáo và thu hút, khẳng định dấu ấn cá nhân trong thế giới nội dung số đầy cạnh tranh.

Bạn đã bao giờ mơ ước biến những dòng chữ khô khan thành những thước phim sống động? Giờ đây, với sự trợ giúp của trí tuệ nhân tạo (AI) và công cụ Stable Diffusion, điều đó hoàn toàn có thể thực hiện được, và quan trọng hơn, hoàn toàn miễn phí! Bài viết này sẽ đưa bạn khám phá thế giới kỳ diệu của việc chuyển đổi văn bản thành video (text-to-video), một lĩnh vực đang phát triển mạnh mẽ với những ứng dụng tiềm năng vô tận.
Giải Mã Cơn Sốt Chuyển Văn Bản Thành Video (Text-to-Video): Tại Sao Ai Cũng Muốn Thử?
Text-to-video không chỉ là một trào lưu công nghệ nhất thời, mà là một bước tiến lớn trong việc dân chủ hóa quy trình sáng tạo nội dung. Trước đây, việc tạo ra một video chất lượng đòi hỏi kỹ năng chuyên môn, phần mềm đắt tiền và thời gian đầu tư đáng kể. Nhưng giờ đây, bất kỳ ai có một ý tưởng và một vài dòng mô tả đều có thể tạo ra một video độc đáo.
Ứng dụng của text-to-video rất đa dạng:
- Marketing và quảng cáo: Tạo ra các video quảng cáo ngắn, thu hút mà không cần đến đội ngũ sản xuất chuyên nghiệp.
- Giáo dục và đào tạo: Biến các bài giảng, hướng dẫn thành các video minh họa sinh động, giúp người học dễ tiếp thu hơn.
- Nghệ thuật và giải trí: Tạo ra các video nghệ thuật độc đáo, thử nghiệm với các phong cách và ý tưởng mới lạ.
- Truyền thông và báo chí: Tạo ra các video tóm tắt tin tức, báo cáo sự kiện một cách nhanh chóng và trực quan.
Với tiềm năng to lớn như vậy, không có gì ngạc nhiên khi text-to-video đang trở thành một lĩnh vực được quan tâm đặc biệt.
Xem thêm:
AnimateDiff: Biến Văn Bản Thành Video Dễ Dàng – Hướng Dẫn Chi Tiết Cho Người Việt
Biến Video Thường Thành Phiên Bản AI Độc Đáo: Khám Phá AnimateDiff Prompt Travel!
Stable Diffusion là một mô hình AI mã nguồn mở, nổi tiếng với khả năng tạo ra hình ảnh chất lượng cao từ văn bản. Gần đây, Stable Diffusion đã được mở rộng để hỗ trợ tạo video, mở ra một kỷ nguyên mới cho việc sáng tạo nội dung.
Điều gì khiến Stable Diffusion trở nên đặc biệt?
- Mã nguồn mở: Điều này có nghĩa là bất kỳ ai cũng có thể sử dụng, sửa đổi và phân phối Stable Diffusion một cách tự do.
- Khả năng tùy biến cao: Bạn có thể tùy chỉnh Stable Diffusion để tạo ra các video với phong cách và nội dung khác nhau.
- Cộng đồng hỗ trợ lớn: Có một cộng đồng lớn mạnh gồm các nhà phát triển và người dùng Stable Diffusion, sẵn sàng chia sẻ kiến thức và kinh nghiệm.
Với Stable Diffusion, bạn không chỉ tạo ra video, bạn còn có thể kiểm soát quá trình sáng tạo và biến những ý tưởng độc đáo nhất thành hiện thực.
Hướng Dẫn Chi Tiết: Biến Văn Bản Thành Video với Stable Diffusion (Miễn Phí!)
Để bắt đầu hành trình sáng tạo video của bạn với Stable Diffusion, bạn cần chuẩn bị một số công cụ và kiến thức cơ bản.
Bước 1: Chuẩn Bị Phần Mềm và Môi Trường
Bạn sẽ cần cài đặt AUTOMATIC1111, một giao diện người dùng đồ họa (GUI) phổ biến cho Stable Diffusion. AUTOMATIC1111 hoạt động trên Windows, Mac và Google Colab. Nếu bạn là người mới bắt đầu, hãy tham khảo hướng dẫn cài đặt nhanh để có cái nhìn tổng quan về Stable Diffusion.
Bước 2: Chọn Phương Pháp Chuyển Văn Bản Thành Video
Hiện tại, có ba phương pháp chính để chuyển văn bản thành video với Stable Diffusion:
- AnimateDiff: Một module được huấn luyện đặc biệt để tạo ra các chuyển động mượt mà và tự nhiên trong video.
- ModelScope: Một mô hình text-to-video dựa trên diffusion, được phát triển bởi Alibaba.
- Deforum: Một công cụ mạnh mẽ để tạo ra các video hoạt hình phức tạp với nhiều tùy chọn tùy chỉnh.
Chúng ta sẽ đi sâu vào từng phương pháp này để bạn có thể lựa chọn phương pháp phù hợp nhất với nhu cầu của mình.
3.1. AnimateDiff: Thổi Hồn Vào Từng Khung Hình
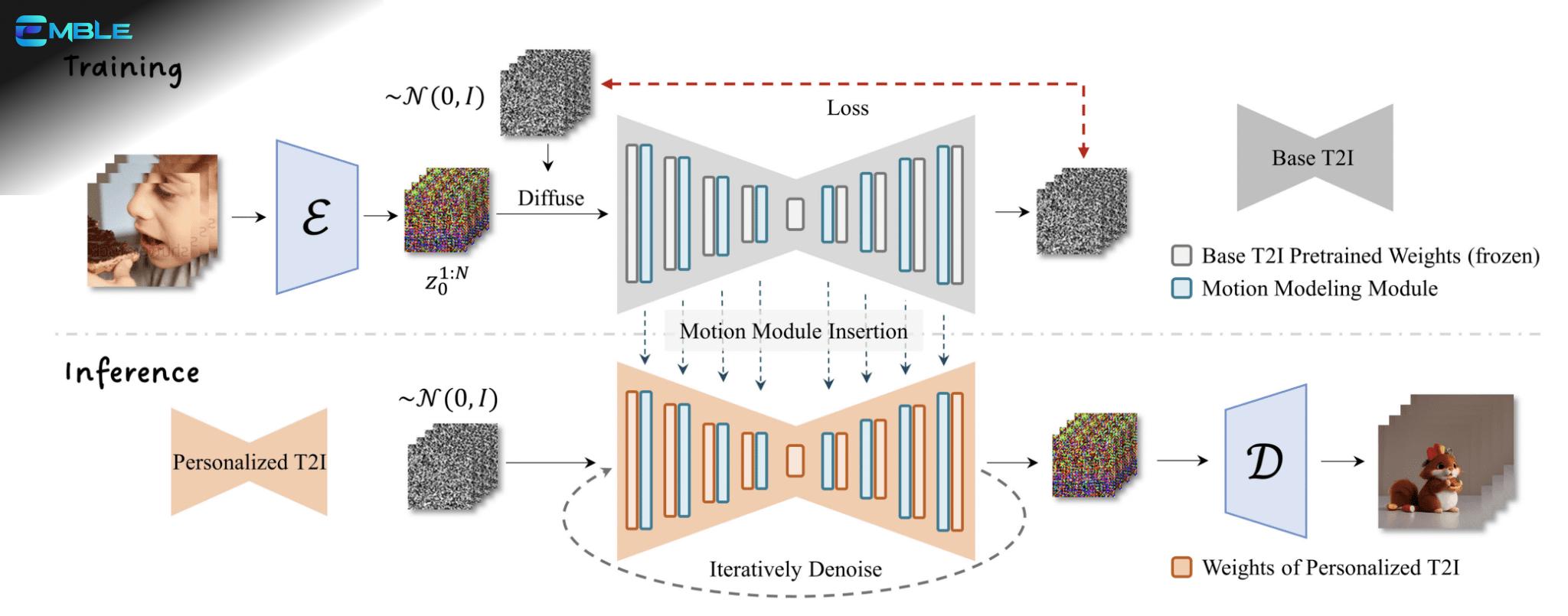
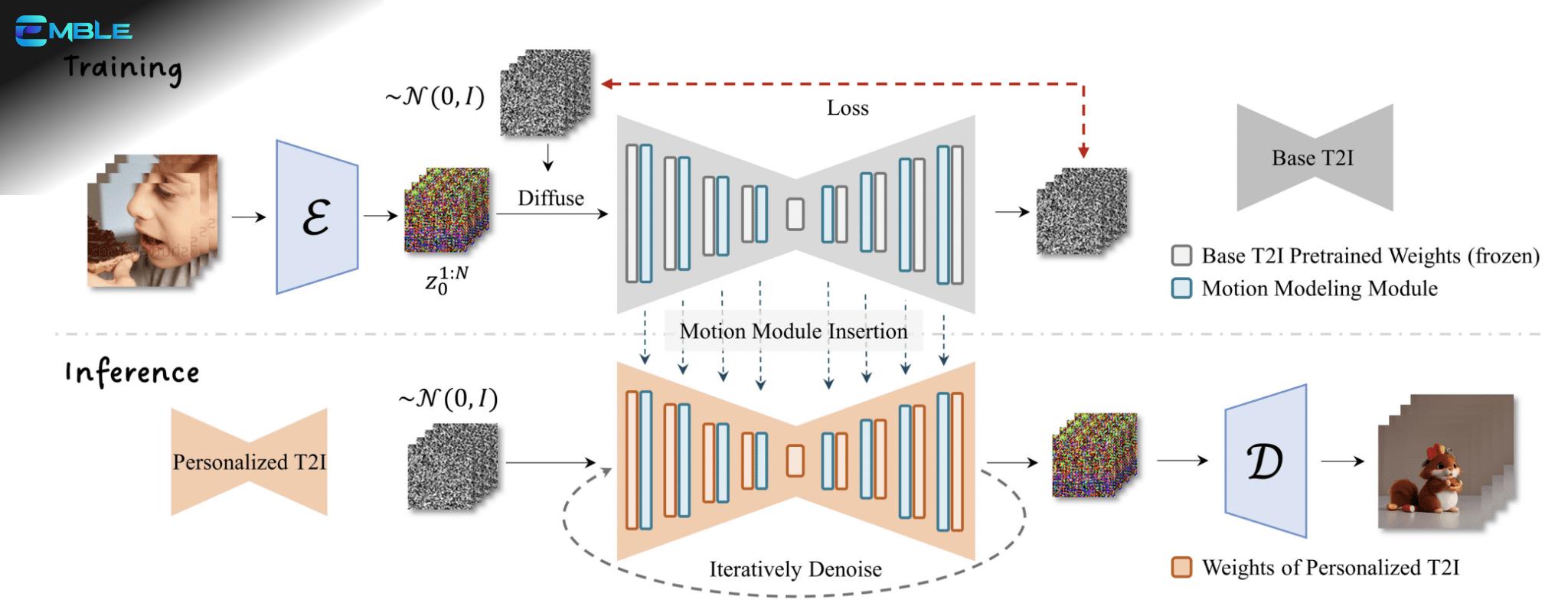
AnimateDiff là một module text-to-video dành cho Stable Diffusion, được huấn luyện bằng cách cho mô hình xem các đoạn video ngắn. Nhờ đó, AnimateDiff học được cách dự đoán khung hình tiếp theo trong video nên như thế nào. AnimateDiff thêm module chuyển động vào bộ dự đoán nhiễu U-Net của mô hình Stable Diffusion để tạo video dựa trên mô tả bằng văn bản.
Cài đặt AnimateDiff
- Google Colab: Chọn AnimateDiff trong danh sách các extension có sẵn.
- Windows/Mac:
- Khởi động AUTOMATIC1111.
- Vào trang Extension.
- Chọn tab Install from URL.
- Nhập URL sau vào ô URL for extension’s git repository:
https://github.com/continue-revolution/sd-webui-animatediff - Đợi thông báo cài đặt thành công.
- Tải các motion model của AnimateDiff từ Hugging Face và lưu vào thư mục
stable-diffusion-webui > extensions > sd-webui-animatediff > model.- Link tải trực tiếp cho v1.5 v2 motion model:
https://huggingface.co/guoyww/animatediff/resolve/main/mm_sd_v15_v2.ckpt - Link tải trực tiếp cho v1.4 motion model:
https://huggingface.co/guoyww/animatediff/resolve/main/mm_sd_v14.ckpt - Link tải trực tiếp cho v1.5 motion model:
https://huggingface.co/guoyww/animatediff/resolve/main/mm_sd_v15.ckpt
- Link tải trực tiếp cho v1.5 v2 motion model:
- Khởi động lại Web-UI.
Sử dụng AnimateDiff
- Trong AUTOMATIC1111, vào trang txt2img.
- Trong phần AnimateDiff:
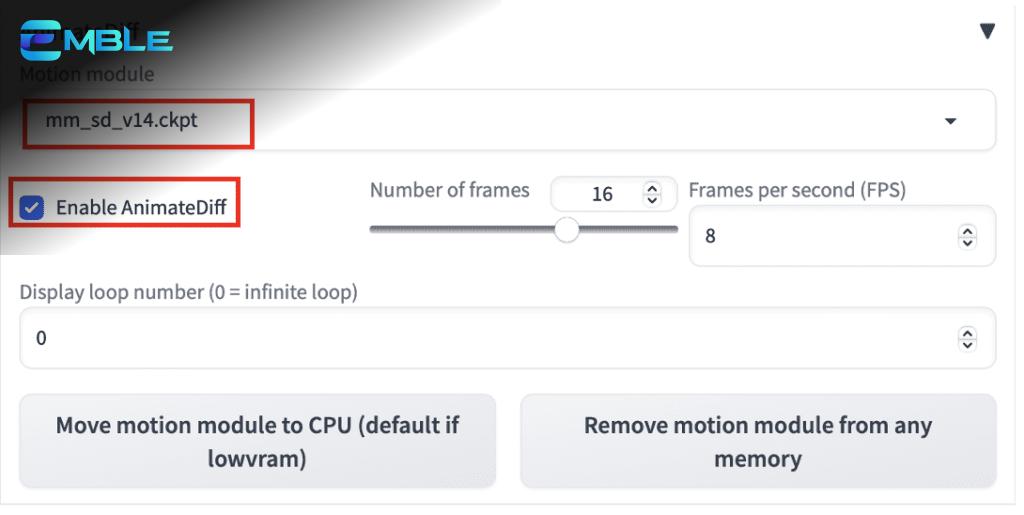
- Enable AnimateDiff: Chọn “Yes”.
- Motion Module: Chọn motion module bạn muốn sử dụng (v1.4 tạo ra nhiều chuyển động hơn, v1.5 tạo ra ảnh rõ nét hơn).
- Nhập prompt và negative prompt như bình thường. Ví dụ:
- Prompt: 1girl, looking at viewer, anime, cherry blossoms
- Negative prompt: disfigured, deformed, ugly
- Chọn model Stable Diffusion v1. Ví dụ: Anything v3.
- CFG: Đặt giá trị cao (10 – 25).
- Sampler: DPM++ 2M Karass.
Mẹo Sử Dụng AnimateDiff
- Tăng CFG scale nếu ảnh bị xám.
- Đổi motion module (v1.4 và v1.5) nếu thấy watermark trên ảnh.
- Sử dụng LoRA với AnimateDiff.
- Giữ số lượng frame ở mức 16 để có hiệu suất tốt nhất.
- Thay đổi prompt nếu bạn thấy hai video ngắn trong một.
3.2. ModelScope: Sức Mạnh Đến Từ Alibaba
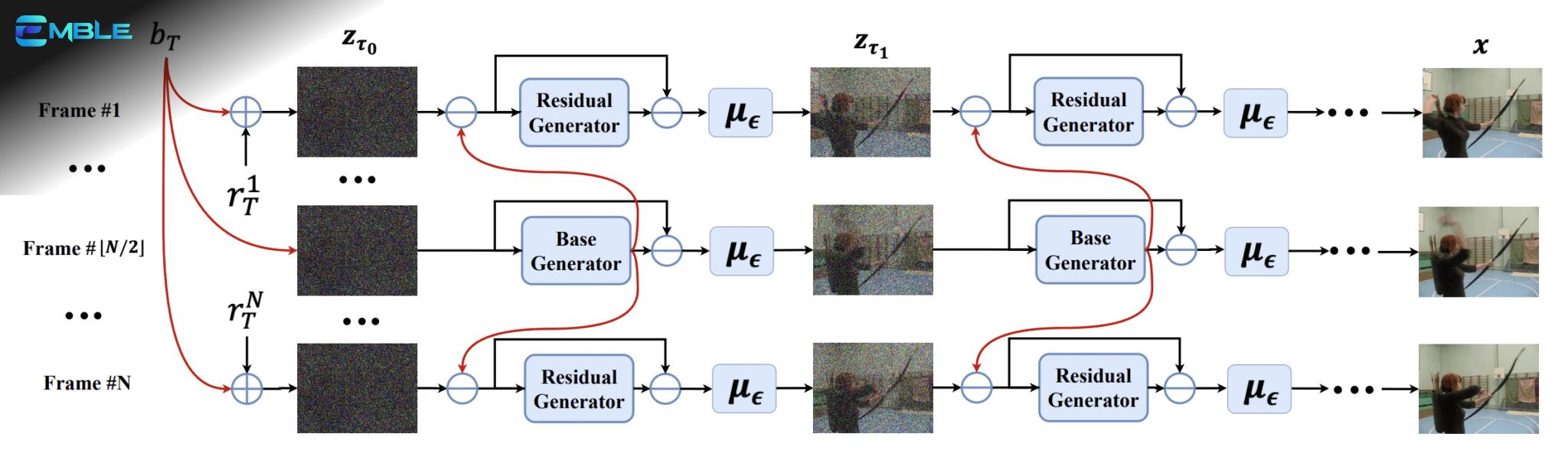
ModelScope là một mô hình text-to-video dựa trên diffusion. Ý tưởng chính của ModelScope là các khung hình của một video thường rất giống nhau. Modelscope là một mô hình latent diffusion. Khung hình đầu tiên bắt đầu dưới dạng một tensor nhiễu ẩn, giống như text-to-image của Stable Diffusion. Điểm mới lạ là mô hình này chia nhiễu thành hai phần: (1) nhiễu cơ bản và (2) nhiễu dư. Nhiễu cơ bản được chia sẻ trên TẤT CẢ các khung hình. Nhiễu dư thay đổi trong mỗi khung hình.
Cài đặt ModelScope
Bạn cần cài đặt extension text2video.
- Google Colab: Chọn extension text2video trong danh sách.
- Windows/Mac:
- Khởi động AUTOMATIC1111.
- Vào trang Extension.
- Chọn tab Install from URL.
- Nhập URL sau vào ô URL for extension’s git repository:
https://github.com/kabachuha/sd-webui-text2video - Đợi thông báo cài đặt thành công.
- Khởi động lại webUI hoàn toàn.
- Tạo cấu trúc thư mục sau:
stable-diffusion-webui\models\text2video\t2v. - Tải các file model text-to-video tại đây và đặt chúng vào thư mục
t2v. Bạn cần 4 file sau:- VQGAN_autoencoder.pth
- configuration.json
- openclippytorch_model.bin
- text2videopytorchmodel.pth
Sử dụng ModelScope
- Trong AUTOMATIC1111, vào trang txt2video.
- Model type: Chọn “ModelScope”.
- Model: Chọn “t2v”.
- Prompt: Nhập prompt mô tả video. Ví dụ: a lion and a man in a suit fighting
- Điều chỉnh Frames để kiểm soát độ dài video.
- Nhấn Generate và đợi hoàn thành. Nhấn Update the video.
Mẹo Sử Dụng ModelScope
- Sử dụng kích thước video 256×256 cho model cơ bản. Các kích thước khác có thể không hoạt động tốt.
- Mô tả những gì bạn muốn THẤY trong video.
- Sử dụng chức năng img2vid để điều chỉnh khung hình ban đầu.
3.3. Deforum: Biến Ý Tưởng Thành Phim Hoạt Hình
Deforum tạo video bằng cách sử dụng các mô hình Stable Diffusion. Nó đạt được tính nhất quán của video thông qua img2img trên các khung hình. Vì đầu vào là nhiều prompt văn bản, nó đủ điều kiện là một pipeline text-to-video.
Cài đặt Deforum
Deforum thường được cài đặt như một extension cho AUTOMATIC1111. Bạn có thể tìm thấy hướng dẫn cài đặt chi tiết trên trang chủ của Deforum hoặc trong cộng đồng Stable Diffusion.
Sử dụng Deforum
Deforum có giao diện phức tạp hơn so với AnimateDiff và ModelScope, nhưng nó cũng cung cấp nhiều tùy chọn tùy chỉnh hơn. Bạn có thể kiểm soát các yếu tố như chuyển động của camera, sự thay đổi của prompt theo thời gian và các hiệu ứng đặc biệt.
Mẹo Sử Dụng Deforum
- Tìm hiểu kỹ các thông số của Deforum để tận dụng tối đa sức mạnh của nó.
- Tham khảo các video hướng dẫn và chia sẻ kinh nghiệm từ cộng đồng Deforum.
- Thử nghiệm với các phong cách và kỹ thuật khác nhau để tạo ra những video độc đáo.
Dưới đây là một số mẹo giúp bạn tạo ra những video chất lượng cao hơn với Stable Diffusion:
- Prompting là chìa khóa: Viết prompt rõ ràng, chi tiết và sáng tạo.
- Thử nghiệm với các model khác nhau: Mỗi model Stable Diffusion có một phong cách riêng.
- Sử dụng negative prompt: Loại bỏ những yếu tố không mong muốn trong video.
- Điều chỉnh các thông số: Tìm hiểu các thông số quan trọng và điều chỉnh chúng để đạt được kết quả tốt nhất.
- Kiên nhẫn và sáng tạo: Text-to-video là một quá trình thử nghiệm. Hãy kiên nhẫn và đừng ngại thử những ý tưởng mới.
Stable Diffusion đã mở ra một kỷ nguyên mới cho việc sáng tạo video, cho phép bất kỳ ai cũng có thể biến những ý tưởng trong đầu thành những thước phim sống động. Bằng cách tận dụng sức mạnh của AI và các công cụ như AnimateDiff, ModelScope và Deforum, bạn có thể tạo ra những video độc đáo và ấn tượng. Hãy sẵn sàng khám phá thế giới kỳ diệu của text-to-video và biến điều không tưởng thành hiện thực!

Sự phát triển của công nghệ tạo video từ văn bản (text to video) bằng Stable Diffusion đang diễn ra với tốc độ chóng mặt. Trong bài viết này, bạn sẽ học cách sử dụng AnimateDiff, một kỹ thuật sản xuất video chi tiết được trình bày trong bài báo khoa học “AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning” của Yuwei Guo và cộng sự.
AnimateDiff là một trong những cách dễ nhất để tạo video bằng Stable Diffusion. Ở dạng cơ bản nhất, bạn chỉ cần viết một đoạn mô tả (prompt), chọn một model và bật AnimateDiff!
AnimateDiff Là Gì Và Tại Sao Nó Lại “Hot”?
AnimateDiff biến một đoạn văn bản mô tả thành một video bằng cách sử dụng mô hình Stable Diffusion. Bạn có thể coi nó như một sự tổng quát hóa nhẹ của việc tạo ảnh từ văn bản: Thay vì tạo ra một hình ảnh, nó tạo ra một video. Công nghệ này mở ra một kỷ nguyên mới cho việc sáng tạo nội dung video, cho phép bất kỳ ai cũng có thể tạo ra những thước phim độc đáo chỉ bằng vài dòng chữ.
AnimateDiff Hoạt Động Như Thế Nào?
AnimateDiff sử dụng một module điều khiển để tác động đến một mô hình Stable Diffusion. Module này được huấn luyện với nhiều đoạn video ngắn khác nhau. Module điều khiển điều chỉnh quá trình tạo ảnh để tạo ra một loạt các hình ảnh trông giống như các đoạn video mà nó đã học.
Giống như ControlNet, module điều khiển của AnimateDiff có thể được sử dụng với BẤT KỲ mô hình Stable Diffusion nào. Hiện tại, chỉ các mô hình Stable Diffusion v1.5 và SDXL được hỗ trợ.
Những Hạn Chế Của AnimateDiff
Vì nó tuân theo chuyển động học được từ dữ liệu huấn luyện, nó tạo ra một chuyển động chung chung thường thấy. Nó sẽ không tạo ra một video tuân theo một chuỗi chuyển động chi tiết trong đoạn mô tả.
Chất lượng chuyển động nhạy cảm với dữ liệu huấn luyện. Nó không thể tạo ảnh động cho đồ họa lạ mắt không có trong dữ liệu huấn luyện. Hãy ghi nhớ điều này khi bạn chọn những gì cần tạo ảnh động. Không phải tất cả các đối tượng và phong cách đều giống nhau.
Tuy nhiên, vẫn có những thủ thuật để cải thiện chuyển động:
- Thay đổi đoạn mô tả trong khi tạo video. Kỹ thuật này được gọi là prompt travel.
- Sử dụng video tham khảo với ControlNet.
Chúng ta sẽ sử dụng AUTOMATIC1111 Stable Diffusion WebUI. Đây là một phần mềm mã nguồn mở miễn phí và phổ biến. Bạn có thể sử dụng GUI này trên Windows, Mac hoặc Google Colab.
Nếu bạn là người mới bắt đầu sử dụng Stable Diffusion, hãy tham khảo Hướng Dẫn Bắt Đầu Nhanh. Nếu bạn là người mới sử dụng AUTOMATIC1111, hãy tham khảo Hướng Dẫn AUTOMATIC1111.
Chúng ta sẽ sử dụng tiện ích mở rộng AnimateDiff cho Stable Diffusion WebUI.
Google Colab
Cài đặt AnimateDiff trong Colab Notebook rất dễ dàng. Tất cả những gì bạn cần làm là chọn tùy chọn AnimateDiff trong phần Extensions.
Windows hoặc Mac
Để cài đặt tiện ích mở rộng AnimateDiff trong AUTOMATIC1111 Stable Diffusion WebUI:
- Khởi động AUTOMATIC1111 Web UI như bình thường.
- Điều hướng đến Trang Extension.
- Nhấp vào tab Install from URL.
- Nhập URL của tiện ích mở rộng vào trường URL for extension’s git repository.
https://github.com/continue-revolution/sd-webui-animatediff- Chờ thông báo xác nhận rằng quá trình cài đặt đã hoàn tất.
- Khởi động lại AUTOMATIC1111.

(Bạn không cần thực hiện bước này nếu bạn đang sử dụng Colab notebook của chúng tôi.)
Bạn cần tải xuống ít nhất một motion module trước khi sử dụng AnimateDiff. Chúng có thể được tìm thấy trên trang Hugging Face của tác giả gốc.
Nếu bạn chỉ muốn tải xuống các phiên bản mới nhất của các motion module, hãy lấy:
- mm_sdxl_v10_beta.safetensors — Phiên bản SDXL
- mm_sd15_v3.safetensors — Phiên bản SD 1.5
Đây là các phiên bản cũ hơn.
- mm_sd_v15_v2.ckpt — Hướng dẫn này cũng sử dụng mô hình v2. Bạn có thể thay thế bằng v3.
- mm_sd_v15.ckpt
- mm_sd_v14.ckpt
Đặt các motion module vào thư mục stable-diffusion-webui > extensions > sd-webui-animatediff > model.
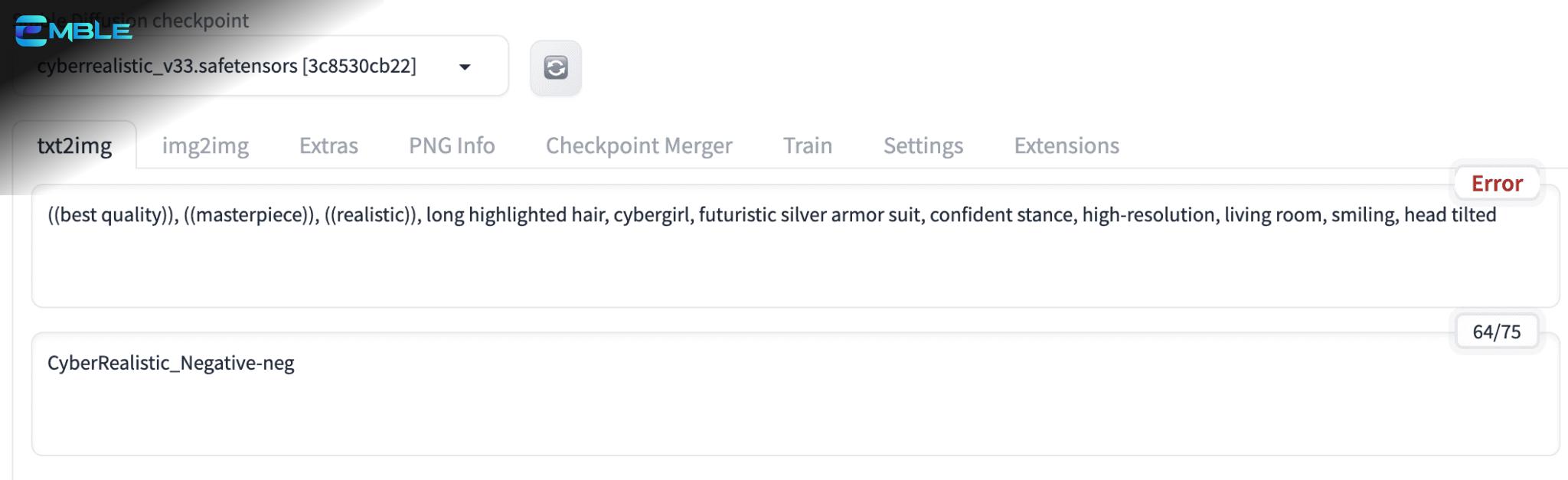
Hãy tạo một video về một cô gái vui vẻ đang thử bộ áo giáp mới của mình trong phòng khách.
Bước 1: Chọn Một Mô Hình Stable Diffusion
Tôi sẽ sử dụng một nhân vật chân thực trong ví dụ này. Hãy sử dụng CyberRealistic v3.3. Tải xuống mô hình và đặt nó trong stable-diffusion-webui > models > Stable-Diffusion.
Trong menu thả xuống Stable Diffusion checkpoint, hãy chọn cyberrealistic_v33.safetensors.
Bước 2: Nhập Cài Đặt txt2img
Trên trang txt2img, hãy nhập các cài đặt sau.
- Prompt:
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted
- Negative Prompt:
CyberRealistic_Negative-neg
Lưu ý: CyberRealistic_Negative là một negative embedding (hướng dẫn cài đặt).
- Steps: 20
- Sampler: DPM++ 2M Karras
- CFG scale: 10
- Seed: -1
- Size: 512×512
Điều chỉnh batch count để tạo nhiều video cùng một lúc.
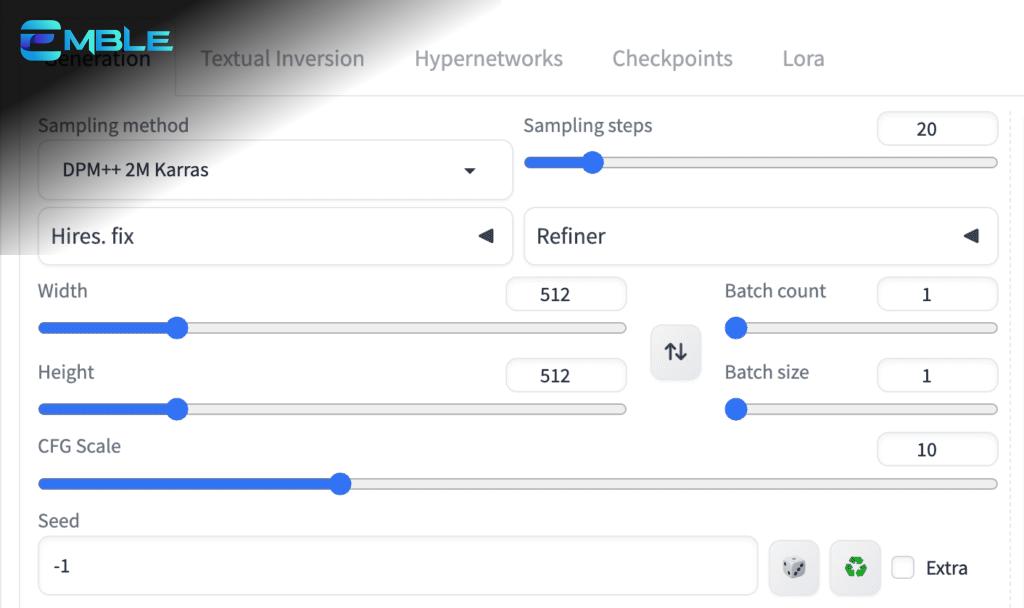
Bước 3: Nhập Cài Đặt AnimateDiff
Trên trang txt2img, hãy cuộn xuống phần AnimateDiff.
Nhập các cài đặt sau.
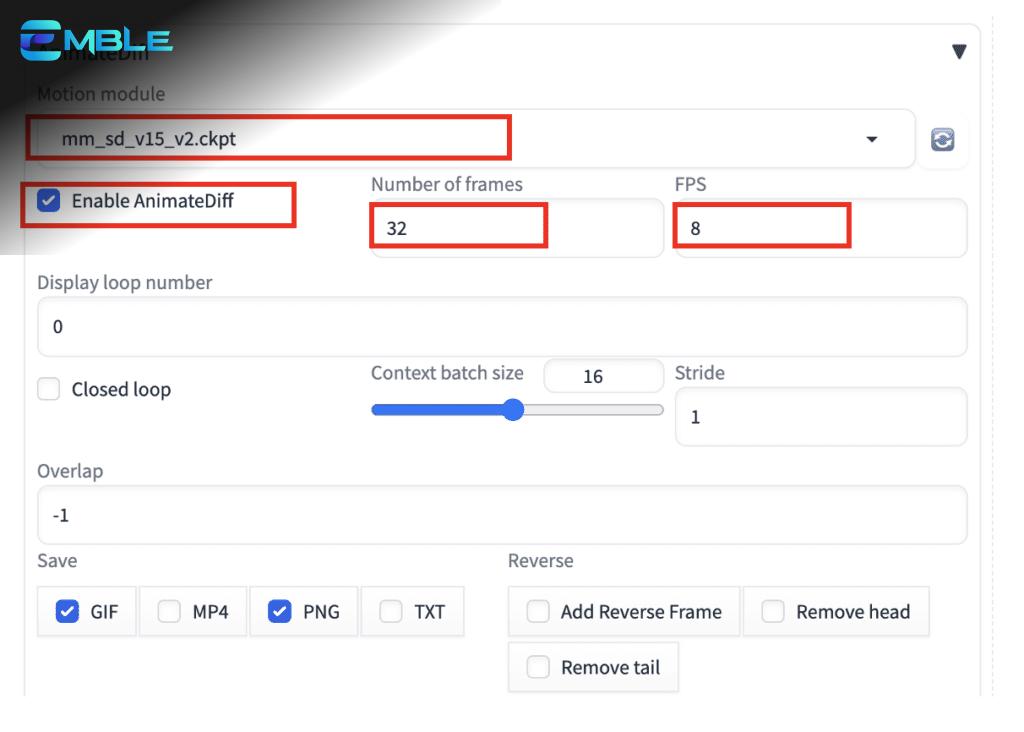
- Motion Module: mm_sd_v15_v2.ckpt
- Enable AnimateDiff: Yes
- Number of frames: 32 (Đây là độ dài của video)
- FPS: 8 (Đây là số khung hình trên giây. Vì vậy, độ dài video là 32 khung hình / 8 fps = 4 giây)
Bạn có thể để phần còn lại ở mặc định.
Chọn MP4 trong tùy chọn Save nếu bạn muốn lưu video MP4.
Bước 4: Tạo Video
Nhấn Generate để tạo video. Bạn sẽ nhận được một cái gì đó tương tự như thế này.
Bạn có thể tìm thấy giải thích chi tiết về các tham số trên trang GitHub. Dưới đây là một số giải thích với các ví dụ minh họa.
Close Loop (Vòng Lặp Khép Kín)
Tùy chọn close loop làm cho video liên tục. Đó là khung hình đầu tiên, giống như khung hình cuối cùng. Vì vậy, bạn sẽ không thấy sự thay đổi đột ngột khi chuyển từ khung hình cuối cùng sang khung hình đầu tiên.
- N: Không sử dụng close loop.
- R-P: Giảm số lượng ngữ cảnh close loop. Prompt travel sẽ KHÔNG được nội suy để trở thành một vòng lặp khép kín.
- R+P: Giảm số lượng ngữ cảnh close loop. Prompt travel SẼ ĐƯỢC nội suy để trở thành một vòng lặp khép kín.
- A: Làm cho khung hình cuối cùng giống như khung hình đầu tiên. Prompt travel SẼ ĐƯỢC nội suy để trở thành một vòng lặp khép kín.
Frame Interpolation (Nội Suy Khung Hình)
Frame interpolation làm cho video trông mượt mà hơn bằng cách tăng số lượng khung hình trên giây.
Đặt Frame Interpolation thành FILM và Interp X thành bội số của FPS. Ví dụ: Đặt nó thành 5 sẽ làm cho video 8 FPS thành 40 FPS.
Vì một số lý do, bạn sẽ cần đặt FPS thành 8 lần 5 = 40 FPS để làm cho ảnh GIF động trông đúng. Nếu không, nó sẽ ở chế độ chuyển động chậm.
Context Batch Size
Context batch size kiểm soát tính nhất quán về thời gian. Context batch size cao hơn làm cho các thay đổi video ít hơn. Giá trị nhỏ làm cho nó thay đổi nhiều hơn.
Nhưng chất lượng dường như giảm đi khi nó khác 16. Vì vậy, tốt hơn là giữ nó ở mức 16.
Bạn có thể điều khiển chuyển động bằng video tham khảo bằng ControlNet.
Hãy sử dụng video tham khảo này làm ví dụ. Mục tiêu là để AnimateDiff theo dõi chuyển động của cô gái trong video.
Bước 1: Tải Video Lên
Trên trang txt2img, hãy cuộn xuống phần AnimateDiff.
Tải video lên canvas Video source.
Bước 2: Nhập Cài Đặt AnimateDiff
Các tham số number of frames và FPS phải khớp với video. Chúng sẽ được điền tự động. Chúng là:
- Number of frames: 96
- FPS: 29
Đừng quên bật AnimateDiff.
- Enable AnimateDiff: Yes
Bước 3: Nhập Cài Đặt txt2img
Các tham số txt2img là:
- Checkpoint model: cyberrealistic_v33.safetensors
- Prompt
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted
- Negative Prompt:
CyberRealistic_Negative-neg
- Steps: 20
- Sampler: DPM++ 2M Karras
- CFG scale: 10
- Seed: -1
- Size: 512×512
Bước 4: Bật ControlNet
Bạn phải bật ControlNet để sao chép video của tham chiếu.
Trong phần ControlNet Unit 0:
Hãy sử dụng DW Openpose.
- Enable: Yes
- Preprocessor: dw_openpose_full
- Model: Openpose
Bước 5: Tạo Video
Nhấn Generate.
(Tiện ích mở rộng AnimateDiff rất khó tính. Nếu nó báo lỗi, hãy thử nhấn Generate lại. Nếu vẫn không hoạt động, hãy khởi động lại A1111 hoàn toàn và thử lại.)

Bạn có thể sử dụng motion LoRA để thêm chuyển động camera vào video. Chúng được sử dụng theo cùng một cách như LoRA tiêu chuẩn.
Cài Đặt Motion LoRA
Bạn có thể tải xuống motion LoRA theo liên kết sau.
Trang tải xuống Motion LoRA
Tải xuống tất cả các tệp có lora là một phần của tên tệp.
Đặt chúng trong stable-diffusion-webui > models > Lora.
Sử Dụng Motion LoRA
Tất cả những gì bạn cần làm là thêm motion LoRA vào prompt. Ví dụ:
Prompt:
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted
Negative prompt:
CyberRealistic_Negative-neg
Bạn thấy nền đang di chuyển sang bên phải, cho thấy camera đang lia sang bên trái.
Nhưng sử dụng LoRA weight 1 dường như tạo ra một artifact ở hậu cảnh. Giảm LoRA weight xuống 0.75 tạo ra kết quả tốt hơn.
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted
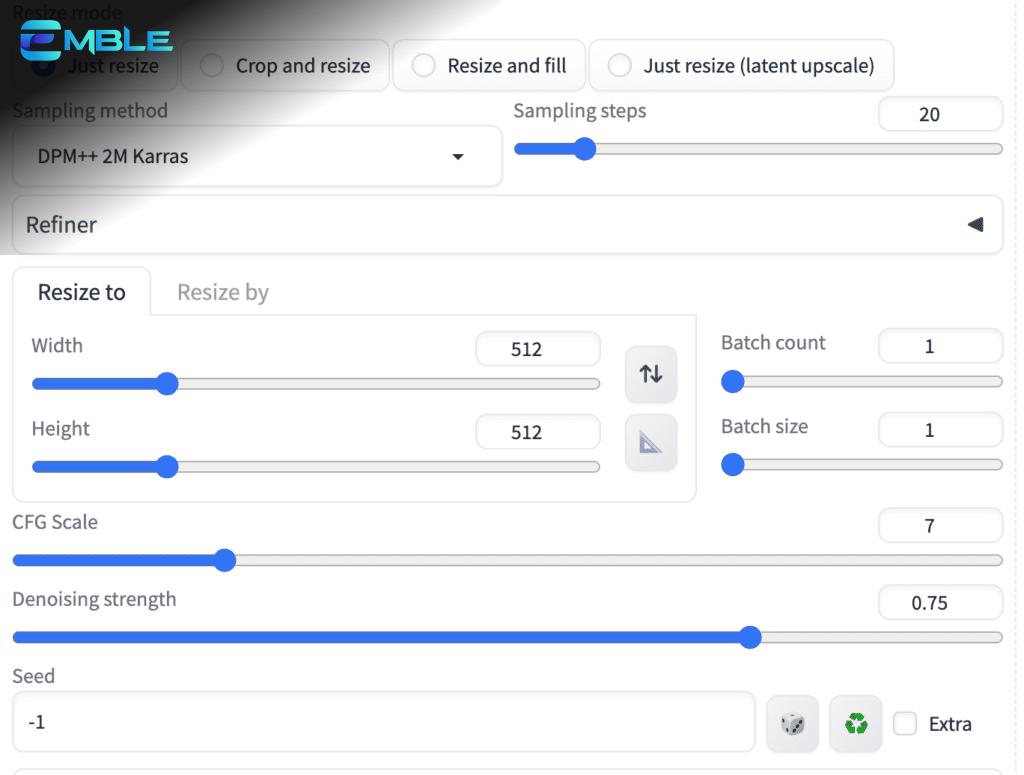
Bạn có thể hướng dẫn bố cục và chuyển động ở một mức độ giới hạn bằng cách sử dụng AnimateDiff với img2img. Trong phương pháp này, bạn có thể xác định hình ảnh ban đầu và cuối cùng của video. Chúng không thể được sử dụng chính xác vì chúng sẽ trải qua quá trình image to image.
Điều hướng đến trang img2img trong AUTOMATIC1111.
Nhập cài đặt img2img.
- Prompt:
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted
- Negative prompt:
CyberRealistic_Negative-neg
Tải hình ảnh ban đầu lên canvas hình ảnh của tab img2img.
- Steps: 20
- Sampler: DPM++ 2M Karras
- CFG scale: 7
- Seed: -1
- Size: 512×512
- Denoising strength: 0.75
- Motion Module: mm_sd_v15_v2.ckpt
- Enable AnimateDiff: Yes
- Number of frames: 32
- FPS: 8
Bạn có thể để phần còn lại ở mặc định.
Tải hình ảnh lên canvas optional last frame.
Nhấn Generate.
Bạn có cảm thấy chuyển động của AnimateDiff hơi thiếu? Bạn có thể tăng chuyển động bằng cách chỉ định các prompt khác nhau tại các thời điểm khác nhau. Tính năng này thường được gọi là prompt travel trong cộng đồng Stable Diffusion.
Đây là cách prompt travel hoạt động. Giả sử bạn chỉ định prompt 1 tại khung hình thứ 1 và prompt 2 tại khung hình thứ 10. Các prompt tại khung hình 1 và khung hình 10 chắc chắn là prompt 1 và prompt 2. Nó nội suy các prompt giữa khung hình 1 và khung hình 10.
Không Có Prompt Travel
Prompt:
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed
Negative prompt:
(worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, normal quality, ((monochrome)), easynegative, badhandv4
Sử Dụng Prompt Travel
Sử dụng prompt ở định dạng sau để sử dụng prompt travel
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed 0: smile 8: (arm over head:1.2) studio lighting
Dòng đầu tiên là tiền tố prompt. Dòng cuối cùng là hậu tố prompt. Chúng được thêm vào đầu và cuối của prompt, tương ứng.
Ở giữa, chúng ta chỉ định các prompt tại các khung hình khác nhau.
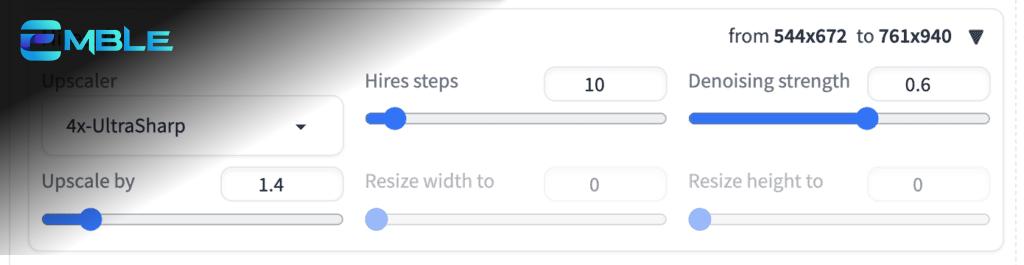
Bạn có thể sử dụng AnimateDiff với Hi Res fix để tăng độ phân giải.
- Upscaler: 4x-UltraSharp
- Hires steps: 10
- Denoising strength: 0.6
- Upscale by: 1.4
AnimateDiff v3 không phải là một phiên bản mới của AnimateDiff, mà là một phiên bản cập nhật của motion module. Tất cả những gì bạn cần làm để sử dụng nó là tải xuống motion module và đặt nó trong thư mục stable-diffusion-webui > models > animatediff. Bạn có thể tải xuống motion module v3 cho AUTOMATIC1111.
Bạn có thể sử dụng Animate v3 motion module theo cùng một cách như v2.
Khi thử nghiệm, tôi không thể nói v3 tốt hơn v2. Chúng tạo ra các chuyển động khác nhau. Bạn có thể giữ cả hai trong hộp công cụ của mình và xem cái nào hoạt động tốt hơn trong quy trình làm việc cụ thể của bạn.
AnimateDiff Cho SDXL: Tạo Video Độ Phân Giải Cao
AnimateDiff SDXL không phải là một phiên bản mới của AnimateDiff, mà là một motion module tương thích với mô hình Stable Diffusion XL. Bạn cần tải xuống motion module SDXL và đặt nó trong thư mục stable-diffusion-webui > models > animatediff.
Bạn có thể sử dụng Animate SDXL motion module theo cùng một cách như các motion module khác. Hãy nhớ đặt nó thành kích thước hình ảnh tương thích với mô hình SDXL, ví dụ: 1024 x 1024.
Bạn có thể sử dụng bất kỳ mô hình SDXL nào, không chỉ mô hình cơ sở.
Tăng Tốc AnimateDiff: Tiết Kiệm Thời Gian Sáng Tạo
Tạo video có thể chậm. AnimateDiff cũng không ngoại lệ. Dưới đây là một vài cách bạn có thể tăng tốc tạo video với AnimateDiff.
LCM LoRA: Tối Ưu Hóa Tốc Độ
LCM LoRA là một mô hình LoRA để tăng tốc Stable Diffusion. Bạn có thể mong đợi quá trình tạo video nhanh hơn gấp 3 lần.
Làm theo hướng dẫn LCM LoRA để cài đặt các module LCM LoRA. Có các phiên bản SD 1.5 và SDXL.
Cài đặt hình ảnh của LCM LoRA khá khác biệt. Điều quan trọng là phải hoàn thiện các cài đặt mà không cần sử dụng AnimateDiff.
SDXL Turbo: Sức Mạnh Của Mô Hình Turbo
Các mô hình SDXL Turbo có cùng kiến trúc với các mô hình SDXL khác, nhưng phương pháp đào tạo Turbo cho phép ít bước sampler hơn. Bạn có thể mong đợi quá trình tạo video nhanh hơn gấp 3 lần.
Điều quan trọng là sử dụng phương pháp lấy mẫu, số bước và CFG scale sau. Nếu không, chất lượng sẽ kém.
Xử Lý Sự Cố AnimateDiff: Giải Quyết Các Vấn Đề Thường Gặp
AnimateDiff Tạo Ra 2 Video Riêng Biệt Thay Vì Một
Prompt có thể quá dài. Trong AUTOMATIC1111 > Settings > Optimization, hãy chọn Pad prompt/negative prompt to be same length.
Kết Luận: Làm Chủ AnimateDiff Để Tạo Video Từ Văn Bản Đột Phá
Với hướng dẫn chi tiết này, bạn đã trang bị cho mình kiến thức và kỹ năng cần thiết để khai thác sức mạnh của AnimateDiff. Hãy bắt đầu thử nghiệm, sáng tạo và biến những ý tưởng văn bản thành những thước phim video ấn tượng. AnimateDiff mở ra một thế giới mới cho việc sáng tạo nội dung, và bạn, với sự kiên nhẫn và đam mê, có thể trở thành một phần của cuộc cách mạng này trong lĩnh vực tạo video từ văn bản.
phần mềm chỉnh sửa video
Biến Video Thường Thành Phiên Bản AI Độc Đáo: Khám Phá AnimateDiff Prompt Travel!

Bạn có bao giờ tự hỏi làm thế nào để biến những thước phim nhàm chán thành những tác phẩm nghệ thuật đầy sáng tạo và độc đáo? Với sự trỗi dậy của trí tuệ nhân tạo (AI), giờ đây bạn có thể dễ dàng biến video thông thường thành những phiên bản hoàn toàn mới lạ chỉ bằng vài thao tác đơn giản. Trong bài viết này, chúng ta sẽ cùng nhau khám phá một kỹ thuật đột phá mang tên AnimateDiff Prompt Travel, một công cụ mạnh mẽ giúp bạn tạo ra những video liền mạch, nhất quán và đầy biến hóa bằng cách sử dụng một video khác làm tham chiếu.
AnimateDiff Prompt Travel Là Gì?
AnimateDiff Prompt Travel là một kỹ thuật sử dụng AI để tạo ra các video có tính nhất quán cao về mặt thời gian và hình ảnh, đồng thời cho phép bạn thay đổi nội dung và phong cách của video theo thời gian bằng cách sử dụng các “prompt” khác nhau. Nói một cách đơn giản, bạn có thể lấy một video bất kỳ, ví dụ như một người đang nhảy múa, và biến nó thành một video hoàn toàn mới với bối cảnh và phong cách khác nhau, ví dụ như người đó đang nhảy múa trên bãi biển, trong vũ trụ, hoặc thậm chí là trong một thế giới hoạt hình.
Kỹ thuật này dựa trên sự kết hợp của ba yếu tố chính:
- AnimateDiff: Công cụ tạo chuyển động video bằng các mô hình Stable Diffusion, đảm bảo tính nhất quán về mặt thời gian.
- ControlNet: Sử dụng video tham chiếu để điều khiển chuyển động và dáng điệu của đối tượng trong video mới.
- Prompt Travel: Thay đổi prompt (lời nhắc) theo thời gian để tạo ra sự đa dạng và biến hóa trong video.
Ưu Điểm Vượt Trội Của AnimateDiff Prompt Travel
So với các kỹ thuật tạo video AI khác, AnimateDiff Prompt Travel sở hữu nhiều ưu điểm vượt trội:
- Tính nhất quán cao: AnimateDiff đảm bảo video được tạo ra có tính nhất quán cao về mặt thời gian, tránh tình trạng giật lag hoặc biến dạng hình ảnh.
- Khả năng điều khiển linh hoạt: ControlNet cho phép bạn điều khiển chuyển động và dáng điệu của đối tượng trong video mới dựa trên video tham chiếu.
- Sáng tạo không giới hạn: Prompt Travel cho phép bạn thay đổi nội dung và phong cách của video theo thời gian, mở ra khả năng sáng tạo vô tận.
- Dễ sử dụng: Với sự hỗ trợ của ComfyUI, việc tạo video bằng AnimateDiff Prompt Travel trở nên dễ dàng hơn bao giờ hết.
Để bắt đầu hành trình sáng tạo video AI với AnimateDiff Prompt Travel, chúng ta sẽ sử dụng ComfyUI, một giao diện người dùng đồ họa mạnh mẽ và linh hoạt. Dưới đây là hướng dẫn chi tiết từng bước:
Bước 1: Cài Đặt Phần Mềm Cần Thiết
Trước khi bắt đầu, bạn cần đảm bảo đã cài đặt các phần mềm sau:
- ComfyUI: Tải và cài đặt ComfyUI theo hướng dẫn trên trang chủ ComfyUI.
- ComfyUI Manager: Cài đặt ComfyUI Manager để quản lý và cài đặt các node tùy chỉnh.
Bước 2: Tải Workflow ComfyUI
Tải xuống workflow JSON ComfyUI cho AnimateDiff Prompt Travel. Bạn có thể tìm thấy workflow này trên các diễn đàn hoặc trang web chia sẻ tài nguyên AI.
Bước 3: Cài Đặt Các Node Bị Thiếu
Mở ComfyUI và kéo thả file workflow JSON vừa tải xuống vào giao diện. Nếu có bất kỳ node nào bị thiếu, ComfyUI Manager sẽ tự động thông báo và cho phép bạn cài đặt chúng.
Bước 4: Chọn Checkpoint Model
Chọn một checkpoint model phù hợp với phong cách video bạn muốn tạo. Bạn có thể tải các checkpoint model từ các trang web như Civitai hoặc Hugging Face. Đặt file checkpoint model vào thư mục ComfyUI > models > checkpoints.
Bước 5: Chọn VAE
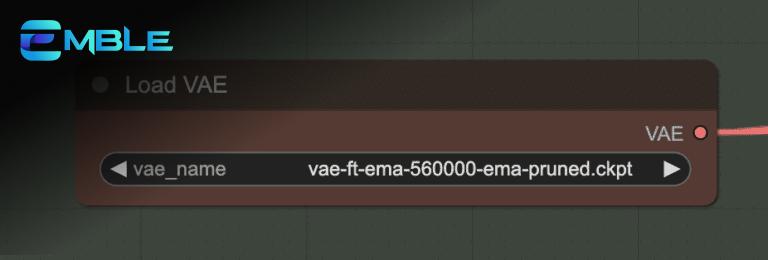
Chọn một VAE (Variational Autoencoder) tương ứng với checkpoint model bạn đã chọn. VAE giúp cải thiện chất lượng hình ảnh và màu sắc của video. Đặt file VAE vào thư mục ComfyUI > models > vae.
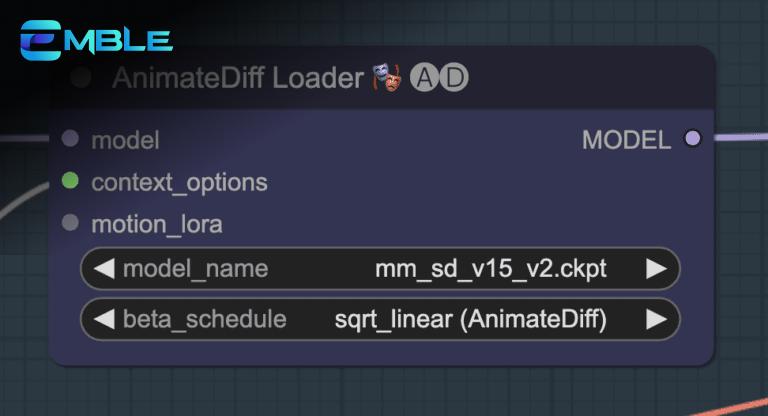
Bước 6: Chọn AnimateDiff Motion Module
Chọn một motion module cho AnimateDiff. Motion module quyết định cách chuyển động được tạo ra trong video. Đặt file motion module vào thư mục ComfyUI > custom_nodes > ComfyUIAnimateDiffEvolved > models.
Bước 7: Chọn Openpose ControlNet Model
Chọn Openpose ControlNet model để trích xuất dáng điệu của người từ video gốc. Đặt file ControlNet model vào thư mục ComfyUI > models > controlnet.
Bước 8: Tải Video Tham Chiếu
Tải video bạn muốn sử dụng làm tham chiếu lên ComfyUI. Video này sẽ được sử dụng để điều khiển chuyển động và dáng điệu của đối tượng trong video mới.
Bước 9: Thiết Lập Prompt
Thiết lập prompt (lời nhắc) cho video. Bạn có thể sử dụng một prompt duy nhất cho toàn bộ video hoặc sử dụng “prompt travel” để thay đổi prompt theo thời gian, tạo ra sự đa dạng và biến hóa.
Bước 10: Tạo Video
Nhấn nút “Queue Prompt” để bắt đầu quá trình tạo video. Thời gian tạo video phụ thuộc vào độ dài của video, độ phức tạp của prompt và cấu hình máy tính của bạn.
Trong quá trình sử dụng AnimateDiff Prompt Travel, bạn có thể gặp phải một số sự cố. Dưới đây là một số cách khắc phục thường gặp:
- Lỗi thiếu node: Đảm bảo bạn đã cài đặt tất cả các node cần thiết bằng ComfyUI Manager.
- Video bị giật lag: Giảm số lượng frame hoặc giảm độ phân giải của video.
- Hình ảnh bị biến dạng: Thay đổi checkpoint model hoặc VAE.
- Chuyển động không tự nhiên: Điều chỉnh motion module hoặc prompt.
AnimateDiff Prompt Travel cho phép bạn tùy biến video theo nhiều cách khác nhau:
- Thay đổi đối tượng: Thay đổi prompt để thay đổi đối tượng trong video.
- Thay đổi bối cảnh: Thay đổi prompt để thay đổi bối cảnh trong video.
- Thay đổi phong cách: Thay đổi checkpoint model và VAE để thay đổi phong cách của video.
- Sử dụng ControlNet khác: Thử nghiệm với các ControlNet khác nhau để điều khiển video theo những cách độc đáo.
Mẹo Sử Dụng AnimateDiff Prompt Travel Hiệu Quả
Để tạo ra những video ấn tượng với AnimateDiff Prompt Travel, hãy lưu ý những mẹo sau:
- Chọn video tham chiếu phù hợp: Video tham chiếu nên có chất lượng tốt và chứa chuyển động rõ ràng.
- Sử dụng prompt chi tiết: Prompt càng chi tiết, video được tạo ra càng giống với ý tưởng của bạn.
- Thử nghiệm với các cài đặt khác nhau: Đừng ngại thử nghiệm với các cài đặt khác nhau để tìm ra những kết quả độc đáo.
- Kiên nhẫn: Quá trình tạo video AI có thể mất nhiều thời gian, đặc biệt là với những video dài và phức tạp.
AnimateDiff Prompt Travel mở ra một kỷ nguyên mới cho việc sáng tạo video AI, kết hợp sức mạnh của AnimateDiff và kỹ thuật Prompt Engineering giúp bạn dễ dàng biến những ý tưởng độc đáo thành hiện thực, tạo ra những video chất lượng cao và đầy tính nghệ thuật.

Chuyển Văn Bản Thành Video Miễn Phí với Stable Diffusion

AnimateDiff: Biến Văn Bản Thành Video Dễ Dàng – Hướng Dẫn Chi Tiết

Biến Video Thường Thành Phiên Bản AI Độc Đáo: Khám Phá AnimateDiff Prompt Travel!

“Phù Phép” Ảnh Chụp Bằng Soft Inpainting: Biến Ảnh Thường Thành Tuyệt Tác AI!

Biến Ảnh Tĩnh Thành Video 3D: Khám Phá Stable Video 3D!

Biến Ảnh Tĩnh Thành Phim: Tạo Video SVD Dễ Dàng Với SD Forge!

Hướng Dẫn Chi Tiết Sử Dụng Kling AI Từ A Đến Z

Tạo Video AI Miễn Phí: MiniMax AI Đã Sẵn Sàng “So Găng” với Sora?
Chuyển Động Cho Video với Kling Ai

Tạo Video AI Chất Lượng Cao với Hunyuan Video và ComfyUI

CodeFormer & ComfyUI: “Cứu Tinh” Cải Thiện Chất Lượng Khuôn Mặt
Khám Phá Bí Mật Làm Mờ Nền Video: Tạo Hiệu Ứng Độc Đáo Cho Video Của Bạn
Chuyển Động Cho Video với Kling Ai
Khám Phá Những Công Cụ Giảm Dung Lượng Video Tuyệt Vời Mà Bạn Không Thể Bỏ Lỡ
Khám Phá Thế Giới Phần Mềm Tạo Hoạt Hình Video: Bí Kíp Tạo Ra Những Thước Phim Ấn Tượng
Chuyển Văn Bản Thành Video Miễn Phí với Stable Diffusion

Biến Ảnh Tĩnh Thành Video “Sống Động”: OmniHuman-1 – Công Nghệ Lip Sync AI Đột Phá!
Khám Phá Công Cụ Ghép Ảnh Vào Video Hấp Dẫn Không Thể Bỏ Qua
Khám Phá Thế Giới Ảo Diệu Với Công Cụ Tạo Hiệu Ứng Ánh Sáng Ảnh
Khám Phá Những Phần Mềm Biên Tập Video Cho YouTube Tốt Nhất Hiện Nay
-
 Các phần mềm nâng cao ảnh bằng AI10 tháng ago
Các phần mềm nâng cao ảnh bằng AI10 tháng agoCodeFormer & ComfyUI: “Cứu Tinh” Cải Thiện Chất Lượng Khuôn Mặt
-
 Tin Nhanh11 tháng ago
Tin Nhanh11 tháng agoKhám Phá Bí Mật Làm Mờ Nền Video: Tạo Hiệu Ứng Độc Đáo Cho Video Của Bạn
-
 phần mềm chỉnh sửa video9 tháng ago
phần mềm chỉnh sửa video9 tháng agoChuyển Động Cho Video với Kling Ai
-
 Tin Nhanh11 tháng ago
Tin Nhanh11 tháng agoKhám Phá Những Công Cụ Giảm Dung Lượng Video Tuyệt Vời Mà Bạn Không Thể Bỏ Lỡ
-
 Tin Nhanh11 tháng ago
Tin Nhanh11 tháng agoKhám Phá Thế Giới Phần Mềm Tạo Hoạt Hình Video: Bí Kíp Tạo Ra Những Thước Phim Ấn Tượng
-
 phần mềm chỉnh sửa video9 tháng ago
phần mềm chỉnh sửa video9 tháng agoChuyển Văn Bản Thành Video Miễn Phí với Stable Diffusion
-
 Các phần mềm nâng cao ảnh bằng AI10 tháng ago
Các phần mềm nâng cao ảnh bằng AI10 tháng agoBiến Ảnh Tĩnh Thành Video “Sống Động”: OmniHuman-1 – Công Nghệ Lip Sync AI Đột Phá!
-
 Tin Nhanh11 tháng ago
Tin Nhanh11 tháng agoKhám Phá Công Cụ Ghép Ảnh Vào Video Hấp Dẫn Không Thể Bỏ Qua